| [Overview][Types][Classes][Index] |
String tokenizer library
The TToken tokenizer is extremely flexible, being able to tokenize quite complex strings. See the unit tests for examples of these. It is also a lot faster than the previous string tokenizer function in tiUtils.
Note:
The tiToken/tiNumToken functions are wrapper functions for the TToken class. Unfortunately they will not be able to take full advantage of the new tokenizer, because tokenized strings will not stay in memory between calls.
Feature List:
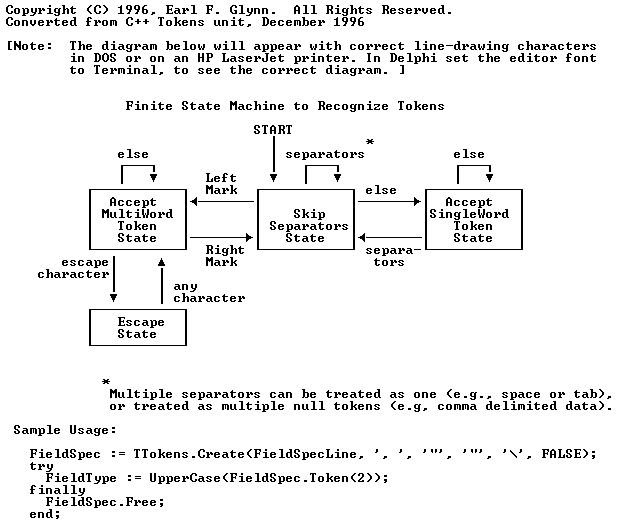
Multiple separators can be specified at once
Multiple separators next to each other can be treated as one separator or as individual separators
Left and Right markers can be specified so strings between those get treated as one token. Markers don't need to be the same.
An Escape string can be specified to remove unwanted strings while tokenized. For example CR and LF can be removed from a long string. Or a \ in Linux scripts mean it is the same line but started on a new line to make it human readable.
Speed ;-)
Separate calls to .Token() doesn't need to retokenize (is that a word?) the original string
The following diagram explains how the states change.